Continual learning in multimodal large language models (MLLMs) aims to sequentially acquire knowledge while mitigating catastrophic forgetting, yet existing methods face inherent limitations: architecture-based approaches incur additional computational overhead and often generalize poorly to new tasks, rehearsal-based methods rely on storing historical data, raising privacy and storage concerns, and conventional regularization-based strategies alone are insufficient to fully prevent parameter interference. We propose Octopus, a two-stage continual learning framework based on History-Free Gradient Orthogonalization (HiFGO), which enforces gradient-level orthogonality without historical task data. Our proposed two-stage finetuning strategy decouples task adaptation from regularization, achieving a principled balance between plasticity and stability. Experiments on UCIT show that Octopus establishes state-of-the-art performance, surpassing prior SOTA by 2.14% and 6.82% in terms of Avg and Last.
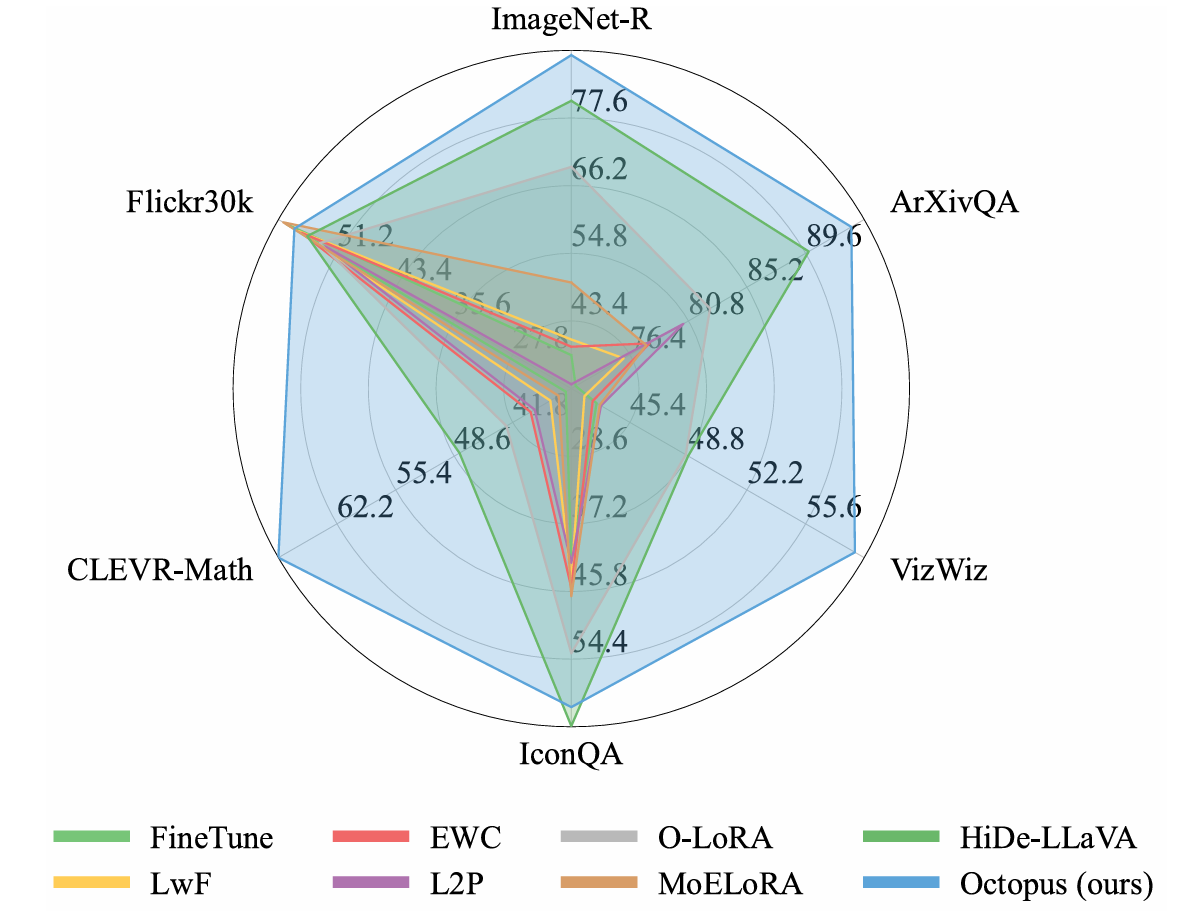
Figure 1. Performance comparison between Octopus (ours) and existing approaches on UCIT in terms of Last. Results demonstrate that Octopus establishes a new SOTA performance and outperforms all competing methods by a substantial margin.
Overall Architecture
The Octopus pipeline is thoughtfully designed to mitigate gradient-level interference across arbitrary task sequences, achieving parameter decoupling purely through optimization geometry.
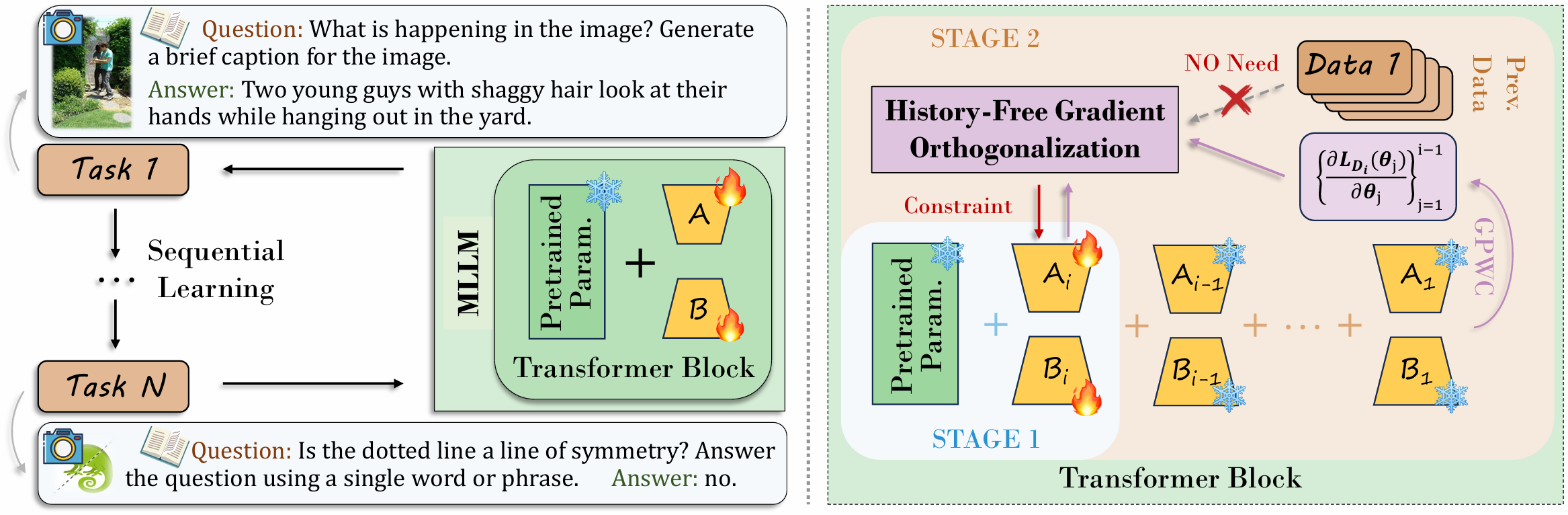
Figure 2. Overall pipeline for continual learning in MLLMs (left) and architecture of our proposed Octopus (right). In the context of continual learning, MLLMs are required to sequentially learn multiple tasks while overcoming the challenge of catastrophic forgetting caused by non-stationary data distributions. To address this, we propose Octopus, which adopts a two-stage fine-tuning paradigm. In the first stage, MLLM learns task-specific knowledge without constraints, enabling full adaptation to current task. In the second stage, we apply History-Free Gradient Orthogonalization (HiFGO) to mitigate parameter interference, while simultaneously constraining the parameter updates within an optimal solution space, thereby maintaining a effective balanced trade-off between plasticity and stability.
Why GPWC Works?
The fundamental insight of HiFGO lies in calculating the gradient sensitivity of historical tasks to steer current optimization. Under strict privacy constraints without old data, we propose GPWC (Gradients of Previous parameters Within Current data distribution).
Theoretical Proof: GPWC is mathematically equivalent to the projection of the previous task's Hessian matrix onto the tangent space of the current task's data manifold.
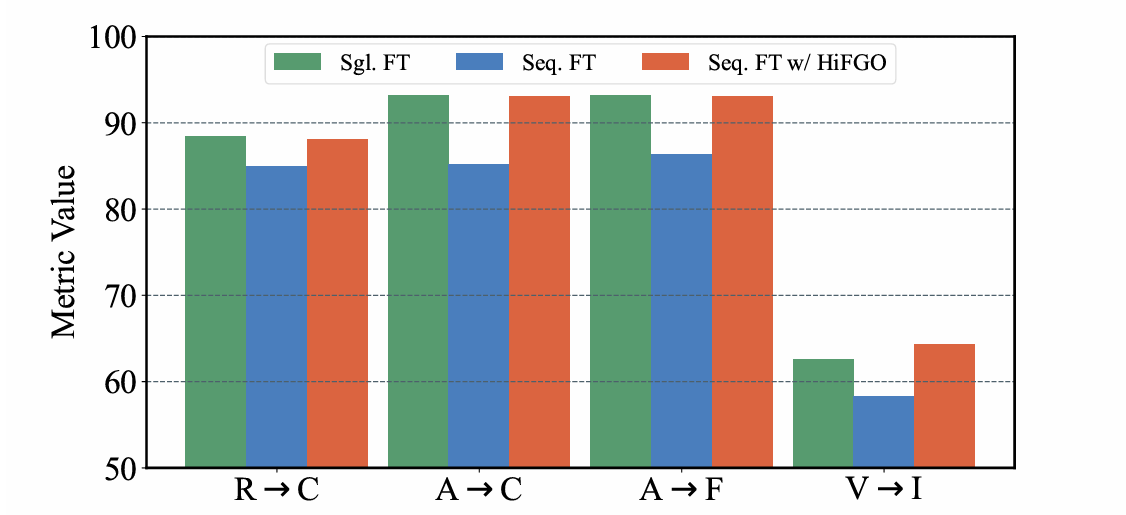
Figure 3. Validity of the HiFGO constraint. Utilizing GPWC successfully restores prior task performance compared to standard sequential fine-tuning.
Figure 4. Comparison of the quadratic form of parameter increment. GPWC guides model updates precisely into low-curvature flat regions of the old tasks.
Two-Stage Finetuning
Stage 1: Unconstrained Adaptation
Inspired by simulated annealing, the model first freely finetunes on the new task data. This phase temporarily ignores stability to maximize plasticity, allowing the model to quickly absorb new feature representations and plunge into the local minimum optimal for the new distributions.
Stage 2: HiFGO Constraints
In the second stage, we activate the HiFGO constraint. This regularized tuning efficiently "pulls back" parameters onto a safe subspace that minimizes interference with the previously learned knowledge, acting as a crucial consolidation step for stability.
Algorithm 1. The formalized execution flow of Two-Stage Finetuning.
Experimental Results
Comprehensive Performance Comparison
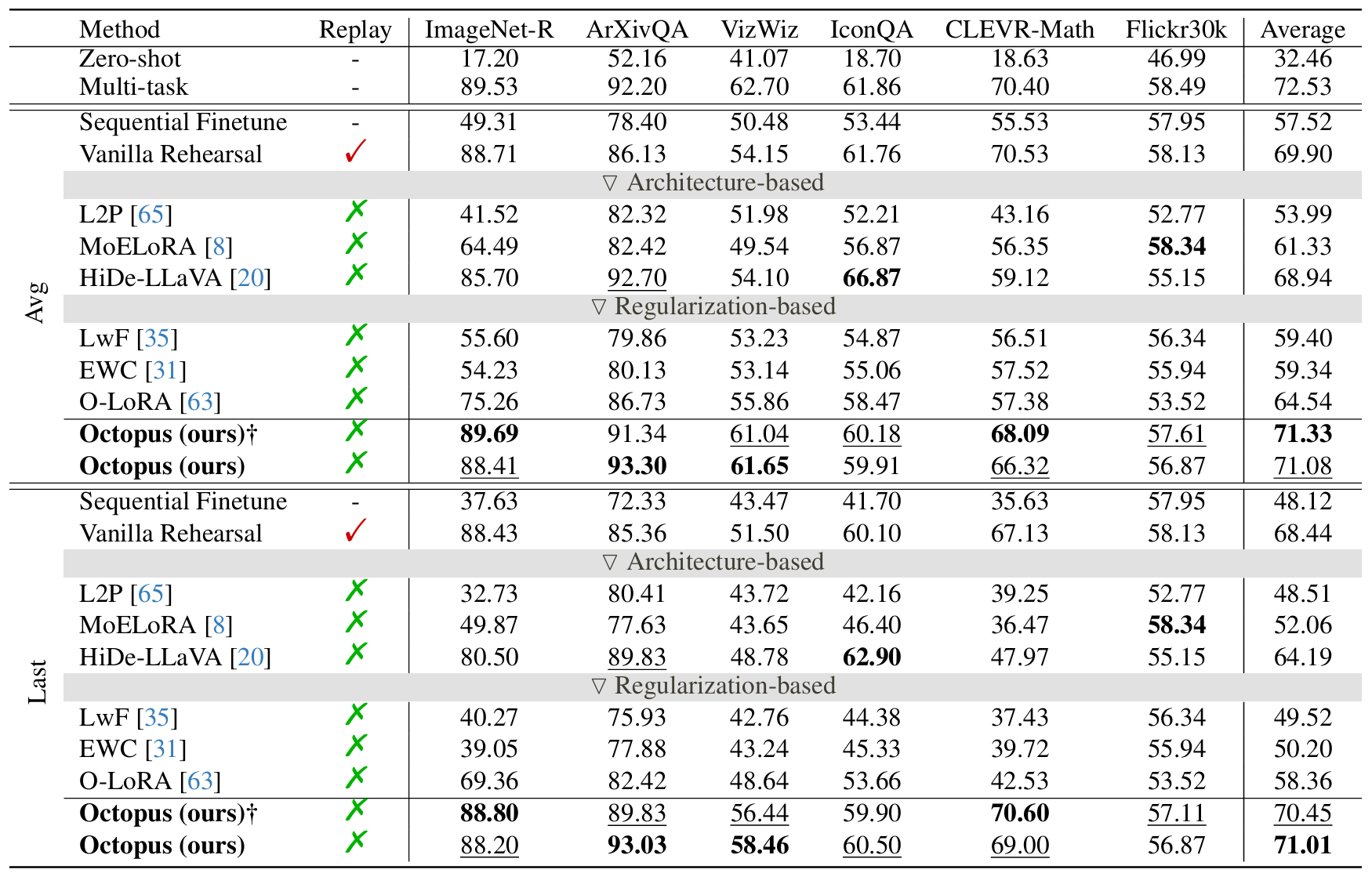
Comparison with various methods on UCIT in terms of Avg and Last. The best and second methods are labeled with bold and underline styles. Zero-shot evaluates pretrained model without finetuning. Multi-task jointly finetunes model across all datasets, whereas Sequential Finetune adapts only one LoRA module sequentially to all tasks. These settings provide an empirical characterization of the lower bound, upper bound, and baseline for continual learning methods.
Backward Transfer (BWT) Analysis
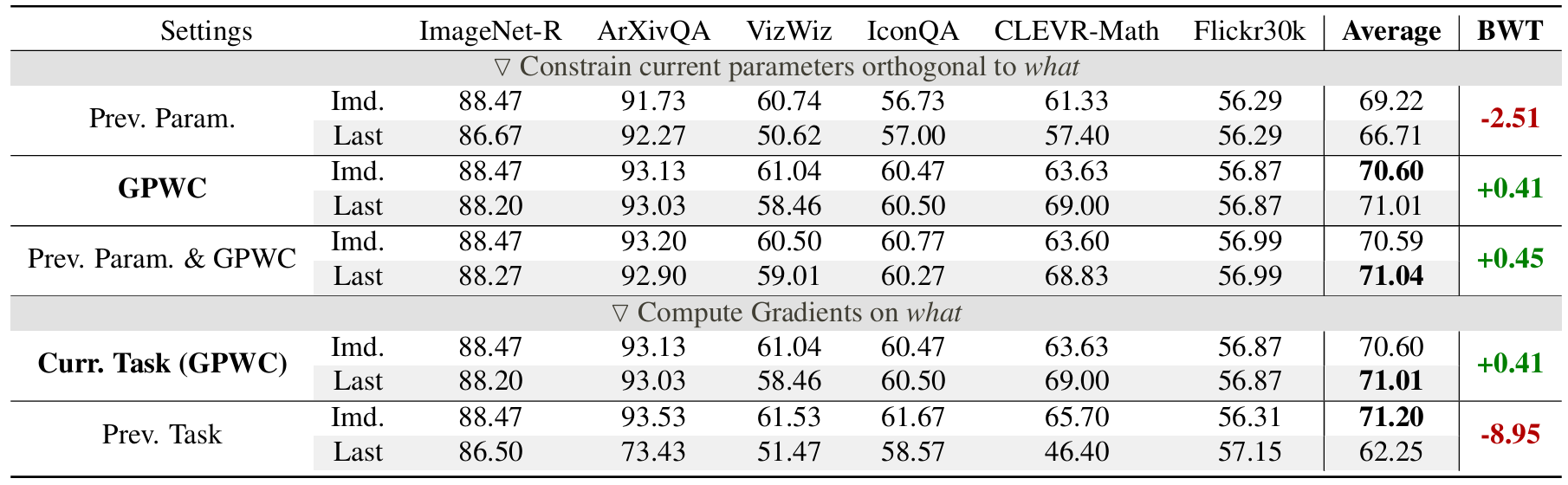
Effectiveness of History-Free Gradient Orthogonalization. We compare the performance of three orthogonalization strategies (orthogonal to param., GPWC or both) and that of two type of gradients (GPWC and gradients of prev. param. on prev. task). Our method is emphasized in bold for clarity.
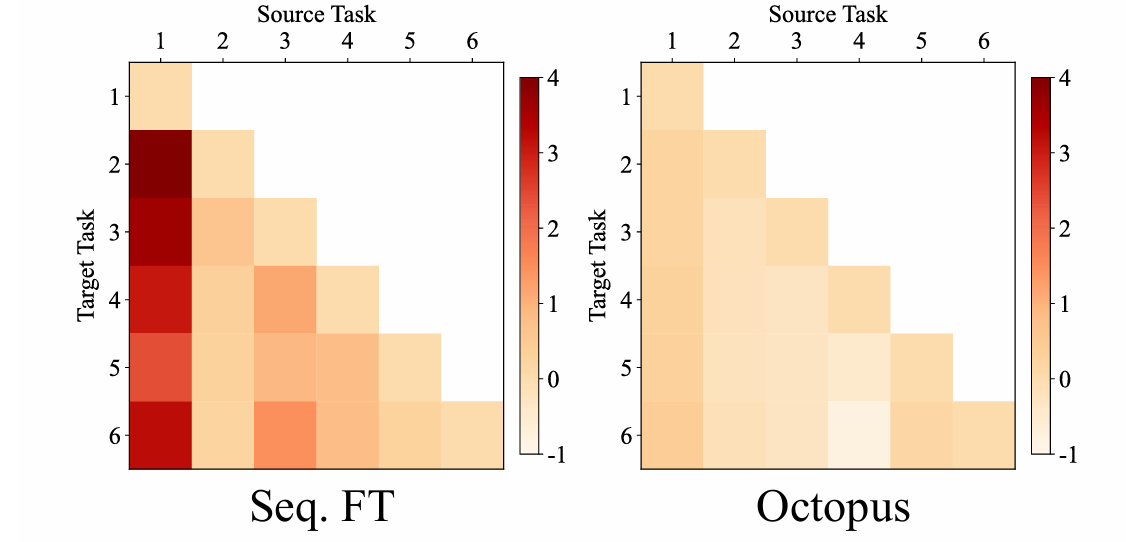
A critical indicator of continual learning capability is Backward Transfer. Instead of suffering from negative transfer, Octopus effectively extracts generalized representations from new tasks that are highly compatible with historical knowledge, yielding an exceptional positive backward transfer (BWT = +0.41).
Robustness and Hyperparameter Sensitivity
Sensitivity analyses confirm that Octopus maintains consistently optimal performance across randomized non-stationary task orders.
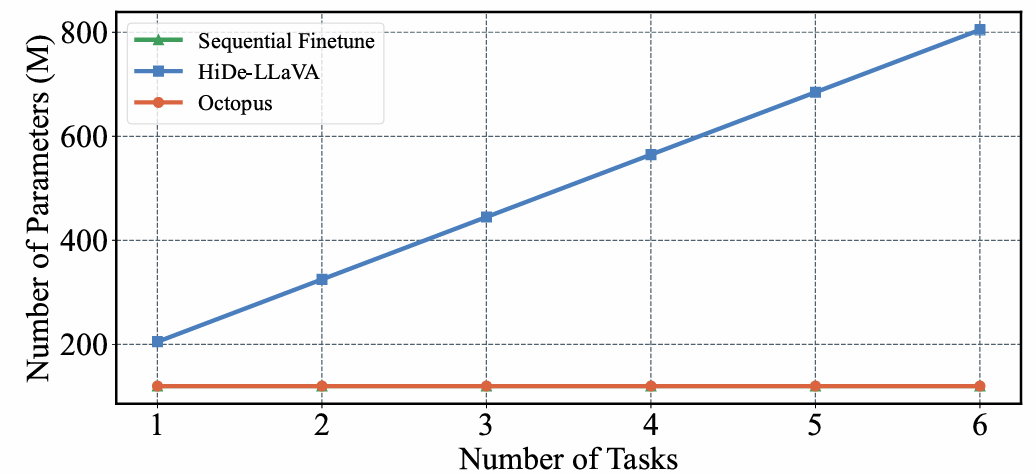
Inference Efficiency
Compared to MoE-based strategies, Octopus utilizes a unified structure, introducing zero additional computational footprint during the inference phase.
Example Analysis
Image Captioning: VizWiz
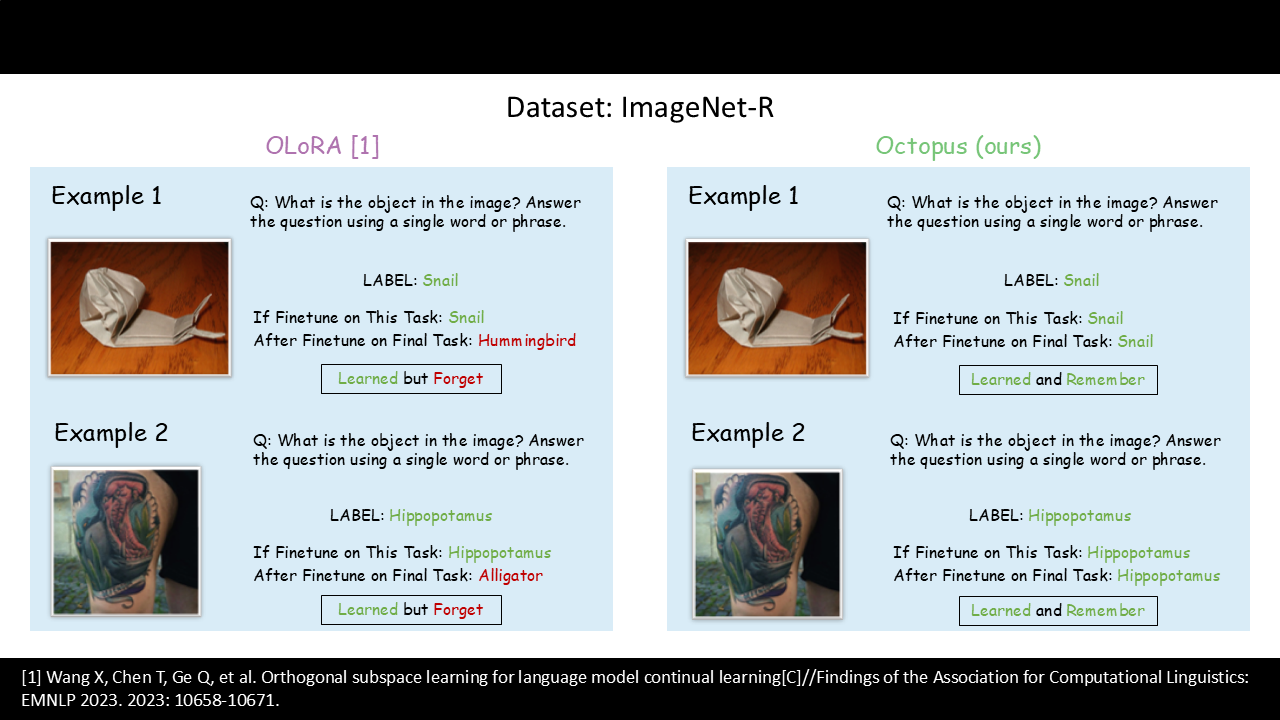
Visual Question Answering: ImageNet-R
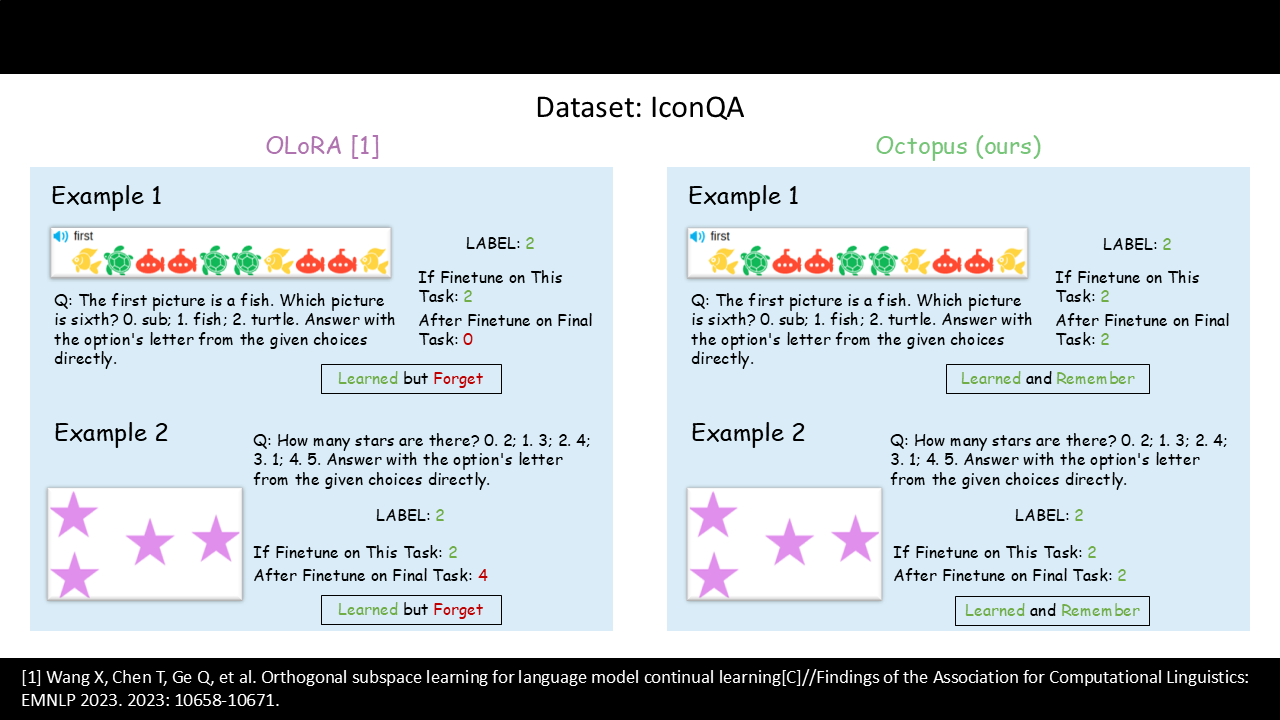
Visual Question Answering: IconQA
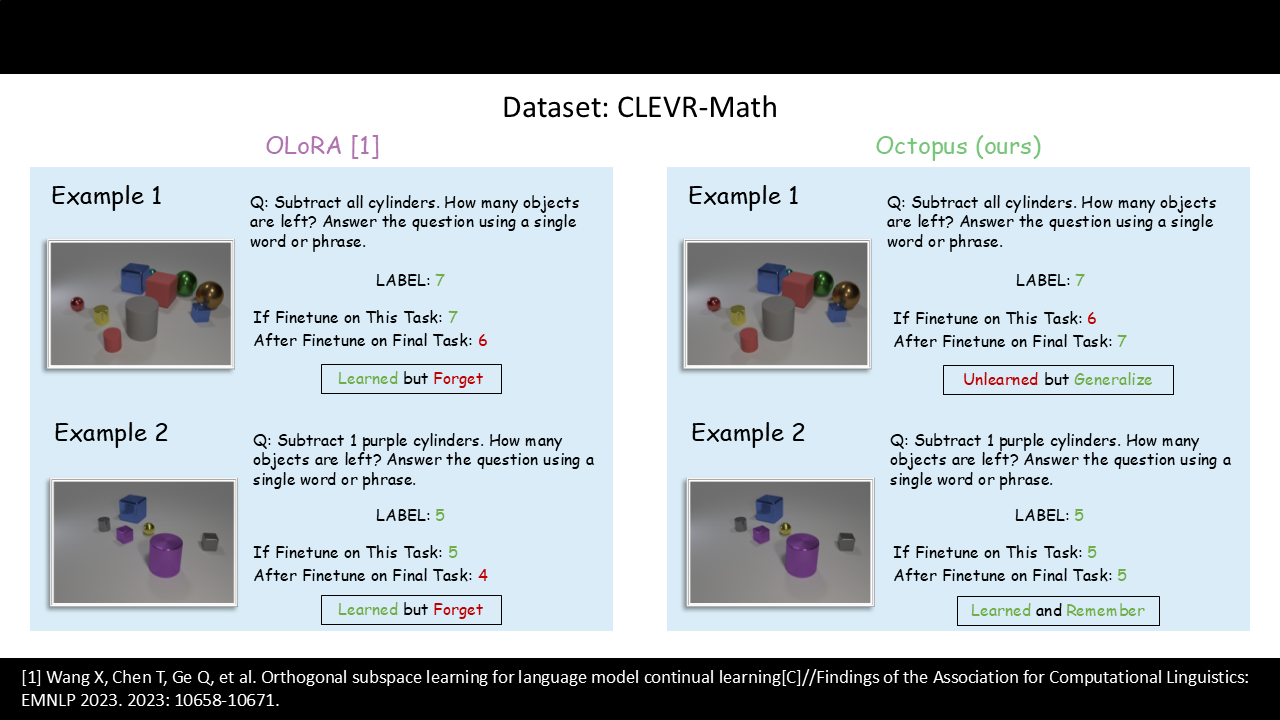
Visual Question Answering: CLEVR-Math
Citation
BibTeX
@article{liu2026octopus,
title={Octopus: History-Free Gradient Orthogonalization for Continual Learning in Multimodal Large Language Models},
author={Liu, Yuehao and Guan, Shanyan and Zhang, Weijia and Shang, Xuanming and Ge, Yanhao and Li, Wei and Ma, Chao},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}
 Octopus: History-Free Gradient Orthogonalization
Octopus: History-Free Gradient Orthogonalization